目录
- 一、Redis 数据一致性问题的产生
- 1. 单节点环境的一致性问题
- 2. 网络分区和宕机
- 3. 并发写入导致的脏数据
- 4. 持久化机制的延迟
- 二、数据一致性模型
- 三、Redis 数据一致性的挑战
- 1. Redis 事务的原子性问题
- 2. 分布式环境中的数据一致性问题
- 3. 持久化机制与数据一致性
- 4. 分布式锁和数据一致性
- 四、处理方案
- 1. 采用合适的数据一致性策略
- 2. 优化事务处理
- 3. 使用 Redis Cluster 提供高可用性
- 4. 合理配置持久化机制
- 总结
Redis 是一个高性能的内存数据库,广泛应用于缓存、会话存储、实时分析等场景。
作为一个 NoSQL 数据库,它的高性能和丰富的数据结构使其成为现代微服务架构中不可或缺的组件。然而,在高并发的环境下,如何保证 Redis 中的数据一致性,成为了一个技术难题。
一、Redis 数据一致性问题的产生
1. 单节点环境的一致性问题
Redis 本身是单线程处理的,这使得在单节点环境下,Redis 在并发场景下对数据的一致性问题相对较少。然而,随着 Redis 被用作分布式缓存,数据一致性问题变得更加复杂。
2. 网络分区和宕机
在分布式环境中,Redis 使用 Redis Sentinel 或 Redis Cluster 实现高可用和故障转移。
当网络发生分区或节点宕机时,Redis 可能会发生数据不一致的情况,尤其是在存在多个写入请求的情况下。
3. 并发写入导致的脏数据
由于 Redis 是基于内存的数据库,并且并不提供像关系型数据库那样的强事务支持,多个并发请求可能会导致数据被覆盖或丢失,尤其在没有恰当的锁或控制措施时。
4. 持久化机制的延迟
Redis 支持 RDB(快照)和 AOF(追加日志)两种持久化机制,但它们都存在一定的延迟。
在发生崩溃或重启时,持久化的数据与内存中的数据可能会发生不一致。
二、数据一致性模型
在讨论 Redis 的一致性问题之前,首先了解数据一致性模型很重要。通常一致性有以下几种模型:
- 强一致性(Strong Consistency):系统在每次读取数据时,能够保证返回的是最新写入的数据。
- 最终一致性(Eventual Consistency):系统保证最终会达到一致状态,但不保证每次读取都能返回最新数据。
- 因果一致性(Causal Consistency):系统保证因果关系一致,不一定每次读取返回最新数据,但读取顺序符合逻辑因果关系。
对于 Redis 来说,在分布式环境中,通常采用最终一致性模型,即数据在最终会达到一致状态,但在网络分区或节点间延迟时,系统允许某些时间窗口内的不一致性。
三、Redis 数据一致性的挑战
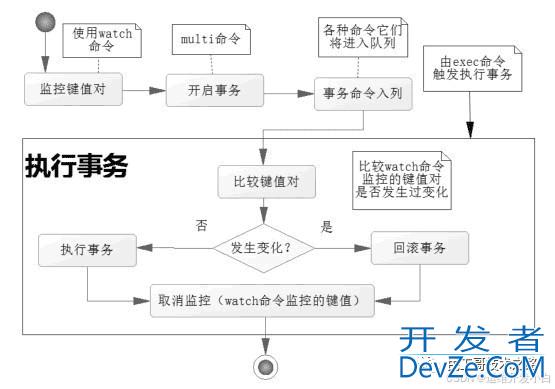
1. Redis 事务的原子性问题
Redis 支持事务功能,主要通过 MULTI、EXEC、WATCH 三个命令实现原子性操作。然而,Redis 的事务并不像关系型数据库的事务那样提供 ACID(原子php性、一致性、隔离性、持久性)特性。
具体地,Redis 事务支持原子性,但没有隔离性(Dirty Read)和持久性(Commitment)。
事务的基本示例:
import redis.clients.jedis.Jedis;
public class RedisTransactionExample {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
// 开启事务
jedis.multi();
// 设置键值
jedis.set("key1", "value1");
jedis.set("key2", "value2");
// 提交事务
jedis.exec();
}
}
上述代码展示了 Redis 事务的基本使用,通过 MULTI 和 EXEC 命令,我们可以确保这些操作的原子性。如果事务过程中某一命令失败,整个事务将会被回滚。
事务的隔离性问题:
Redis 不提供事务级别的隔离性。这意味着在一个事务提交之前,其他客户端可能会看到未提交的数据,这就可能产生脏读、不可重复读等问题。
2. 分布式环境中的数据一致性问题
Redis 在分布式环境中使用 Redis Sentinel 或 Redis Cluster 来提供高可用性和自动故障转移。但在故障转移过程中,由于数据同步延迟,可能导致某些数据的不一致。
3. 持久化机制与数据一致性
Redis 支持两种主要的持久化机制:RDB(Redis 数据库快照)和 AOF(追加日志)。
RDB 会在指定时间间隔内生成数据快照,而 AOF 会将每个写操作追加到日志中。
- RDB 持久化:通过快照将内存中的数据定期保存到磁盘。在发生故障时,Redis 可以恢复到最后一次的快照状态,但如果故障发生时数据没有被快照保存,数据就会丢失。
- AOF 持久化:通过追加写操作日志来保存数据,每当 Redis 重启时,AOF 会通过重放操作日志来恢复数据。AOF 提供了更高的持久化保证,但也会带来性能开销。
RDB 与 AOF 比较:
| 特性 | RDB | AOF |
|---|---|---|
| 性能 | 快速,但可能丢失部分数据 | 更慢,数据恢复更快 |
| 数据丢失风险 | 丢失最近一次快照后的数据 | 丢失未写入磁盘的操作 |
| 恢复时间 | 较短,加载快照 | 较长,重放操作日志 |
| 适用场景 | 适合偶尔进行全量备份的场景 | 适合需要更高数据安全性的场景 |
4. 分布式锁和数据一致性
在高并发环境下,多个进程同时访问 Redis 可能会产生数据不一致的问题。
为了解决这个问题,Redis 提供了分布式锁的实现。使用 Redis 的 SETNX 命令可以实现一个简单的分布式锁。
分布式锁实现示例:
import redis.clients.jedis.Jedis;
public class RedisDistributedLock {
pripythonvate static final String LOCK_KEY = "lock_key";
public static boolean acquireLock(Jedis jedis) {
long currentTime = System.currentTimeMillis();
long expireTime = currentTime + 10000; // 锁超时10秒
// 尝试加锁
String result = jedis.set(LOCK_KEY, String.valueOf(expireTime), "NX", "PX", 10000);
return "OK".equals(result);
}
public static void releaseLock(Jedi编程s jedis) {
j编程客栈edis.del(LOCK_KEY);
}
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
if (acquireLock(jedis)) {
System.out.println("Lock acquired, performing critical operation...");
// 执行关键操作
releaseLock(jedis);
} else {
System.out.println("Unable to acquire lock, try again later.");
http://www.devze.com }
}
}
通过上述代码,我们使用 SETNX 命令来尝试获取锁,并在操作完成后释放锁,确保在分布式环境下对共享资源的访问是串行化的,从而避免数据不一致的情况。
四、处理方案
1. 采用合适的数据一致性策略
在分布式系统中,选择合适的数据一致性模型至关重要。Redis 通常适用于最终一致性的场景,而不是强一致性。
使用分布式锁、缓存失效策略等技术可以帮助我们管理一致性问题。
2. 优化事务处理
在 Redis 中,事务并不提供隔离性,开发者需要根据实际业务场景,选择合适的操作方式。
例如,对于需要保证事务隔离的场景,可以使用分布式锁机制来确保操作的顺序性。
3. 使用 Redis Cluster 提供高可用性
使用 Redis Cluster 或 Sentinel 来保证 Redis 的高可用性,合理配置分片和故障转移策略,减少网络分区带来的不一致性问题。
4. 合理配置持久化机制
根据数据的重要性选择合适的持久化策略。
对于不太重要的数据,可以选择 RDB 来减少性能开销;而对于关键数据,则可以使用 AOF 进行频繁持久化,确保数据不丢失。
总结
在高并发分布式环境中,Redis 的数据一致性问题通常是开发者面临的一大挑战。通过合理配置 Redis 的事务、分布式锁、高可用方案和持久化策略,开发者可以在保证高性能的同时,减少数据不一致的风险。
Redis 强调的是最终一致性,因此在设计系统时,要明确业务对一致性的需求,并根据实际场景采取合适的策略。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程客栈(www.devze.com)。

 加载中,请稍侯......
加载中,请稍侯......
精彩评论