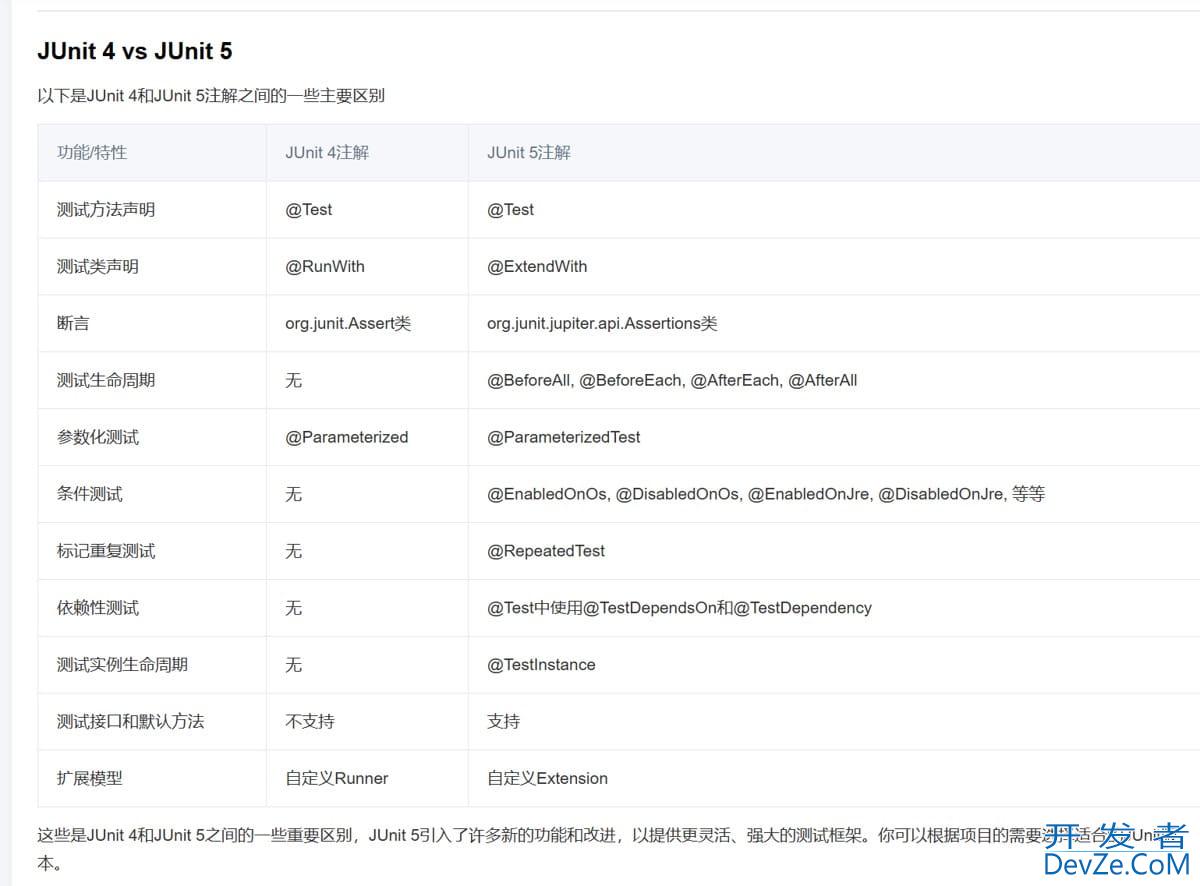
目录
- 一、小文件简单解析
- 二、大文件解析
- 三、复杂结构解析
查阅了些资料自己记录一下
一、小文件简单解析
对于小文件的 XML 解析,我们可以使用 Go 标准库中的encoding/xml包来实现。
假设我们有一个名为demo.xml的文件,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<config>
&www.devze.comlt;smtpServer>smtp.163.com</smtpServer>
<smtpPort>25</smtpPort>
<sender>user@163.com</sender>
<senderPasswd>123456</senderPasswd>
<receivers flag="true">
<age>16</age>
<user>Mike_Zhang@live.com</user>
<user>test1@qq.com</user>
<script>
<![CDATA[
function matchwo(a,b) {
if (a < b && a < 0) then {
return 1;
} else {
http://www.devze.com return 0;
}
}
]]>
</script>
</receivers>
</config>
对应的main.go文件代码如下:
package main
import (
"fmt"
"io/ioutil"
"encoding/xml"
)
// 定义结构体来映射 XML 结构
type SConfig struct {
XMLName xml.Name `xml:"config"`
SmtpServer string `xml:"smtpServer"`
SmtpPort int `xml:"smtpPort"`
Sender string `xml:"sender"`
SenderPasswd string `xml:"senderPasswd"`
Receivers SReceivers `xml:"receivers"`
}
type SReceivers struct {
Age int `xml:"age"`
Flag string `xml:"flag,attr"`
User []string `xml:"user"`
Script string `xml:"script"`
}
func readXml(path string) {
// 直接读取文件内容,ioutil 内部处理打开和关闭操作
data, err := ioutil.ReadFile(path)
if err!= nil {
fmt.Println("读文件出错!", err)
return
}
// 初始化结构体变量
v := SConfig{}
err = xml.Unmarshal(data, &v)
if err!= nil {
fmt.Printf("error: %v", err)
return
}
// 打印解析后的结果
fmt.Println("SmtpServer : ", v.SmtpServer)
fmt.Println("SmtpPort : ", v.SmtpPort)
fmt.Println("Sender : ", v.Sender)
fmt.Println("SenderPasswd : ", v.SenderPasswd)
fmt.Println("Receivers.Flag : ", v.Receivers.Flag)
fmt.Println("Receivers.Age : ", v.Receivers.Age)
fmt.Println("Receivers.Script : ", v.Receivers.Script)
for i, element := range v.Receivers.User {
fmt.Println(i, element)
}
}
func main() {
readXml("demo.xml")
}
运行这段代码后,输出如下:
SmtpServer : smtp.163.com
SmtpPort : 25Sender : user@163.comSenderPasswd : 123456Receivers.Flag : trueReceivers.Age : 16Receivers.Script :function matchwo(a,b) {
if (a < b && a < 0) then { return 1; } else { return 0; } }0 Mike_Zhang@live.com
1 test1@qq.com
二、大文件解析
当处理较大的 XML 文件时,我们可以采用流式解析的方式,以避免一次性将整个文件加载到内存中。
同样以demo.xml文件为例,内容不变。
main.go文件代码如下:
package main
import (
"fmt"
"encoding/xml"
"bufio"
"os"
"io"
)
// 定义结构体来映射 XML 结构
type SConfig struct {
XMLName xml.Name `xml:"config"`
SmtpServer string `xml:"smtpServer"`
SmtpPort int `xml:"smtpPort"`
Sender string `xml:"sender"`
SenderPasswd string `xml:"senderPasswd"`
Receivers SReceivers `xml:"receivers"`
}
type SReceivers struct {
Age int `xml:"age"`
Flag string `xml:"flag,attr"`
User []string `xml:"user"`
Script string `xml:"script"`
}
func readXml(path string) {
// 打开文件
file, errOpen := os.Open(path)
if errOpen!= nil {
fmt.Println("打开文件异常!", errOpen)
return
}
defer file.Close()
// 创建带缓存的 Reader
reader := bufio.NewReader(file)
decoder := xml.NewDecoder(reader)
for t, err := decoder.Token(); err == nil || err == io.EOF; t, err = decoder.Token() {
switch token := t.(type) {
case xml.StartElement:
name := token.Name.Local
fmt.Println(name)
if name == "config" {
// 解析 config
var sConfig = SConfig{}
configErr := decoder.DecodeElement(&sConfig, &token)
if configErr!= nil {
fmt.Println("解析错误:")
fmt.Println(configErr)
} else {
fmt.Println(sConfig)
}
return
}
}
}
}
func main() {
readXml("demo.xml")
}
输出结果为:
config
{{ config} smtp.163.com 25 user@163.com 123456 {16 true [Mike_Zhang@live.com test1@qq.com]function matchwo(a,b) {
if (a < b && a < 0) then { &nbTBCWRKmKmssp; return 1; } else { return 0; } }}}
三、复杂结构解析
对于复杂结构的 XML 文件,我们可以使用第三方库github.com/beevik/etree来进行解析。
假设我们有一个名为bookstores.xml的文件,内容如下:
<bookstore xmlns:p="urn:schemas-books-com:prices">
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<p:price>30.00</p:price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<p:price>29.99</p:price>
</book>
<book category="WEB">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagar编程客栈ajan</author>
<year>2003</year>
<p:price>49.99</p:price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<p:price>39.95</p:price>
</book>
</bookstore>
main.go文件代码如下:
package main
import (
"fmt"
"github.com/beevik/etree"
)
func readXml(path string) {
doc := etree.NewDocument()
if err := doc.ReadFromFile(path); err!= nil {
panic(err)
}
root := doc.SelectElement("bookstore")
fmt.Println("ROOT element:", root.Tag)
for _, book := range root.SelectElements("book") {
fmt.Println("CHILD element:", book.Tag)
if title := book.SelectElement("title"); title!= nil {
lang := title.SelectAttrValue("lang", "unknown")
fmt.Printf(" TITLE: %s (%s)\n", title.Text(), lang)
}
for _, attr := range book.Attr {
fmt.Printf(" ATTR: %s=%s\n", attr.Key, attr.Value)
}
}
}
func main() {
readXml("bookstores.xml")
}
输出结果为:
ROOT element: bookstore
CHILD element: book TITLE: Everyday Italian (en) ATTR: category=COOKINGCHILD element: book TITLE: Harry Potter (en) ATTR: category=CHILDRENCHILD element: book TITLE: XQuery Kick Start (en) ATTR: category=WEBCHILD element: book TITLE: Learning XML (en) ATTR: category=WEB
使用流数据进行解析xml文件如果所包含标签存在会有字段读取丢失清空这种情况进行如下编写
package main
import (
"encoding/xml"
"fmt"
"io"
"os"
)
// 定义结构体来映射html片段中的pre标签
type HTMLPre struct {
XMLName xml.Name `xml:"htmlpre"`
Text string `xml:",innerxml"`
}
// 定义结构体来映射Rule元素
type XCCDFRule struct {
XMLName xml.Name `xml:"Ruljse"`
ID string `xml:"id,attr"`
Title string `xml:"title"`
Description string `xml:"description"`
HTMLPre []HTMLPre `xml:"htmlpre"`
}
func parseRule(reader io.Reader) (*XCCDFRule, error) {
decoder := xml.NewDecoder(reader)
decoder.Strict = false
decoder.AutoClose = xml.HTMLAutoClose
decoder.Entity = xml.HTMLEntity
var rule XCCDFRule
for {
token, err := decoder.Token()
if err == io.EOF {
break
} else if err!= nil {
return nil, err
}
switch se := token.(type) {
case xml.StartElement:
if se.Name.Local == "Rule" {
if err := decoder.DecodeElement(&rule, &se); err!= nil {
return nil, err
}
// 进一步解析description中的HTML内容
if err!= nil {
return nil, err
}
return &rule, nil
}
}
}
return nil, fmt.Errorf("Rule element not found")
}
func main() {
file, err := os.Open("your_file.xml")
if err!= nil {
fmt.Println("打开文件错误:", err)
return
}
defer file.Close()
rule, err := parseRule(file)
if err!= nil {
fmt.Println("解析错误:", err)
return
}
fmt.Printf("规则ID: %s\n", rule.ID)
fmt.Printf("规则标题: %s\n", rule.Title)
fmt.Printf("规则描述: %s\n", rule.Description)
}
在这个改进后的代码中:
- 定义了
HTMLPre结构体来映射<htmlpre>标签的内容,包括标签内的文本(使用xml:",innerxml"来获取标签内的所有XML内容作为字符串)。 - 在
XCCDFRule结构体中添加了HTMLPre字段来存储解析后的<htmlpre>标签内容列表。 - 在
parseRule函数中,解码Rule元素后,调用parseDescription函数来进一步解析description字段中的HTML内容,提取<htmlpre>标签内的文本并存储到rule.HTMLPre列表中。 parseDescription函数创建了一个新的XML解析器来解析description字符串中的内容,专门查找<html:pre>标签并解码其内容。
请注意,这只是一种处理方式,根据你的实际需求,可能需要进一步调整和扩展代码来处理XML中更复杂的HTML嵌套结构或其他类型的内容。同时,将"your_file.xml"替换为实际的XML文件路径。
到此这篇关于golang进行xml文件解析的文章就介绍到这了,更多相关golang xml文件解析内容请搜索编程客栈(www.devze.com)以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程客栈(www.devze.com)!



 加载中,请稍侯......
加载中,请稍侯......
精彩评论