目录
- 一、Selenium技术架构解析
- 二、环境搭建与基础配置
- 1. 组件安装
- 2. 驱动配置
- 3. 基础操作模板
- 三、动态内容抓取核心策略
- 1. 智能等待机制
- 2. 交互行为模拟
- 3. 反爬应对方案
- 四、实战案例:电商评论抓取
- 五、性能优化与异常处理
- 1. 资源管理
- 2. 异常捕获
- 六、进阶方案对比
- 七、总结
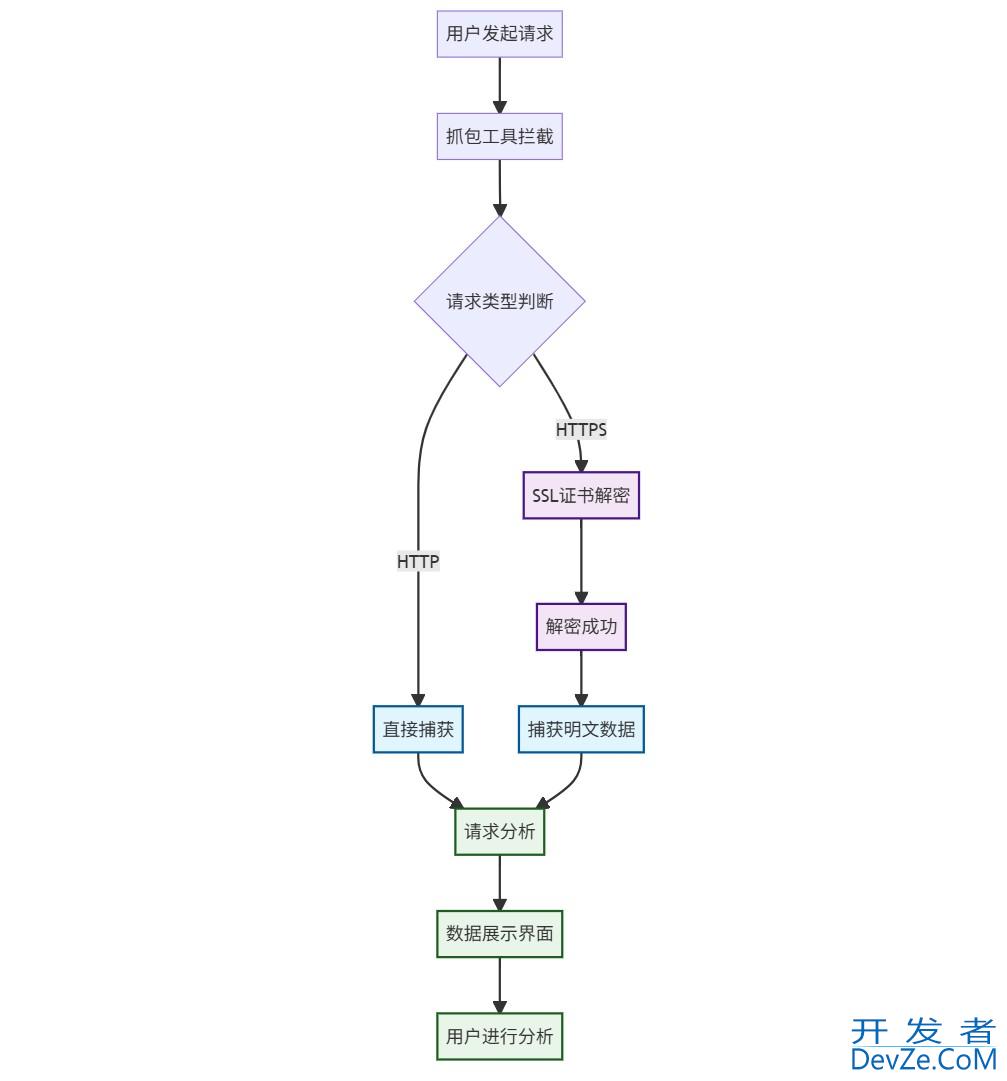
在Web数据采集领域,动态渲染页面已成为现代网站的主流形式。这类页面通过JavaScript异步加载内容,传统请求库(如requests)无法直接获取完整数据。Selenium作为浏览器自动化工具,通过模拟真实用户操作,成为解决动态渲染页XcOsNeCr面抓取的核心方案。本文将从技术原理、环境配置、核心功能到实战案例,系统讲解Selenium在python动态爬虫中的应用。
一、Selenium技术架构解析
Selenium通过WebDriver协议与浏览器内核通信,其架构可分为三层:
- 客户端驱动层:Python代码通过selenium库生成操作指令
- 协议转换层:WebDriver将指令转换为浏览器可执行的jsON Wire Protocol
- 浏览器执行层:Chrome/Firefox等浏览器内核解析协议并渲染页面
这种架构使得Selenium具备两大核心优势:
- 全要素渲染:完整执行javascript/css/AJAX等前端技术栈
- 行为模拟:支持点击、滚动、表python单填写等真实用户操作
二、环境搭建与基础配置
1. 组件安装
# 安装Selenium库 pip install selenium # 下载浏览器驱动(以Chrome为例) # 驱动版本需与浏览器版本严格www.devze.com对应 # 下载地址:https://chromedriver.chromium.org/downloads
2. 驱动配置
from selenium import webdriver # 方式一:指定驱动路径 driver = webdriver.Chrome(executable_path='/path/to/chromedriver') # 方式二:配置环境变量(推荐) # 将chromedriver放入系统PATH路径 driver = webdriver.Chrome()
3. 基础操作模板
driver = webdriver.Chrome()
try:
driver.get("https://example.com") # 访问页面
element = driver.find_element(By.ID, "search") # 元素定位
element.send_keys("Selenium") # 输入文本
element.submit() # 提交表单
print(driver.page_source) # 获取渲染后源码
finally:
driver.quit() # 关闭浏览器
三、动态内容抓取核心策略
1. 智能等待机制
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
# 显式等待:直到元素存在(最多等待10秒)
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".dynamic-content"))
)
# 隐式等待:全局设置元素查找超时
driver.implicitly_wait(5)
2. 交互行为模拟
# 滚动加载
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 鼠标悬停
from selenium.webdriver.common.action_chains import ActionChains
hover_element = driver.find_element(By.ID, "dropdown")
ActionChains(driver).move_to_element(hover_element).perform()
# 文件上传
file_input = driver.find_element(By.XPATH, "//input[@type='file']")
file_input.send_keys("/path/to/local/file.jpg")
3. 反爬应对方案
# 代理配置
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--proxy-server=http://user:pass@proxy.example.com:8080')
driver = webdriver.Chrome(options=chrome_options)
# 随机User-Agent
from fake_useragent import UserAgent
ua = UserAgent()
chrome_options.add_argument(f'user-agent={ua.random}')
# Cookies管理
driver.add_cookie({'name': 'session', 'value': 'abc编程客栈123'}) # 设置Cookie
print(driver.get_cookies()) # 获取所有Cookies
四、实战案例:电商评论抓取
场景:抓取某电商平台商品评论(需登录+动态加载)
实现代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 初始化配置
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 无头模式
options.add_argument('--disable-blink-features=AutomationControlled') # 反爬规避
driver = webdriver.Chrome(options=options)
try:
# 登录操作
driver.get("https://www.example.com/login")
driver.find_element(By.ID, "username").send_keys("your_user")
driver.find_element(By.ID, "password").send_keys("your_pass")
driver.find_element(By.ID, "login-btn").click()
time.sleep(3) # 等待登录跳转
# 访问商品页
driver.get("https://www.example.com/product/12345#reviews")
# 滚动加载评论
for _ in range(5):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
# 提取评论数据
comments = driver.find_elements(By.CSS_SELECTOR, ".review-item")
for idx, comment in enumerate(compythonments, 1):
print(f"Comment {idx}:")
print("User:", comment.find_element(By.CSS_SELECTOR, ".user").text)
print("Content:", comment.find_element(By.CSS_SELECTOR, ".content").text)
print("Rating:", comment.find_element(By.CSS_SELECTOR, ".rating").get_attribute('aria-label'))
print("-" * 50)
finally:
driver.quit()
关键点说明:
- 使用无头模式减少资源消耗
- 通过disable-blink-features参数规避浏览器自动化检测
- 组合滚动加载与时间等待确保内容完整加载
- CSS选择器精准定位评论元素层级
五、性能优化与异常处理
1. 资源管理
# 复用浏览器实例(适用于多页面抓取)
def get_driver():
if not hasattr(get_driver, 'instance'):
get_driver.instance = webdriver.Chrome()
return get_driver.instance
# 合理设置超时时间
driver.set_page_load_timeout(30) # 页面加载超时
driver.set_script_timeout(10) # 异步脚本执行超时
2. 异常捕获
from selenium.common.exceptions import (
NoSuchElementException,
TimeoutException,
StaleElementReferenceException
)
try:
# 操作代码
except NoSuchElementException:
print("元素未找到,可能页面结构变化")
except TimeoutException:
print("页面加载超时,尝试重试")
except StaleElementReferenceException:
print("元素已失效,需重新定位")
六、进阶方案对比
| 方案 | 适用场景 | 优势 | 局限 |
|---|---|---|---|
| Selenium | 复杂交互/严格反爬 | 功能全面、行为真实 | 资源消耗大、速度较慢 |
| Playwright | 现代浏览器/精准控制 | 异步支持、API现代化 | 学习曲线陡峭 |
| Puppeteer | Node.js生态/无头优先 | 性能优异、Chrome调试协议 | 非Python原生支持 |
| Requests-html | 简单动态内容 | 轻量快速 | 对复杂SPA支持有限 |
七、总结
Selenium作为动态页面抓取的瑞士军刀,其核心价值体现在:
- 完整还原浏览器渲染流程
- 灵活模拟各类用户行为
- 强大的反爬虫应对能力
在实际项目中,建议遵循以下原则:
- 优先分析页面加载机制,对可API直采的数据避免使用Selenium
- 合理设置等待策略,平衡稳定性与效率
- 结合代理池和请求头轮换提升抗封能力
- 对关键操作添加异常重试机制
通过掌握本文所述技术要点,开发者可构建出稳定高效的动态数据采集系统,应对90%以上的现代网页抓取需求。对于超大规模爬取场景,可考虑结合Scrapy框架实现分布式Selenium集群,进一步提升系统吞吐量。
到此这篇关于Python Selenium动态渲染页面和抓取的使用指南的文章就介绍到这了,更多相关Python Selenium动态渲染页面和抓取内容请搜索编程客栈(www.devze.com)以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程客栈(www.devze.com)!


 加载中,请稍侯......
加载中,请稍侯......
精彩评论