python+selenium编写实现爬虫过程: 1.爬虫循环处理table表,2.table表分页处理,3.网页table所有内容循环处理4.获取隐藏的href超链接内容,5.所有数据本地csv保存,[详细]
golang unique包和字符串内部化优化技巧
C++ STL中容器string超详细讲解
深度解析C# 弃元模式从语法糖到性能利器
SpringBoot中缓存@Cacheable出错的问题解决
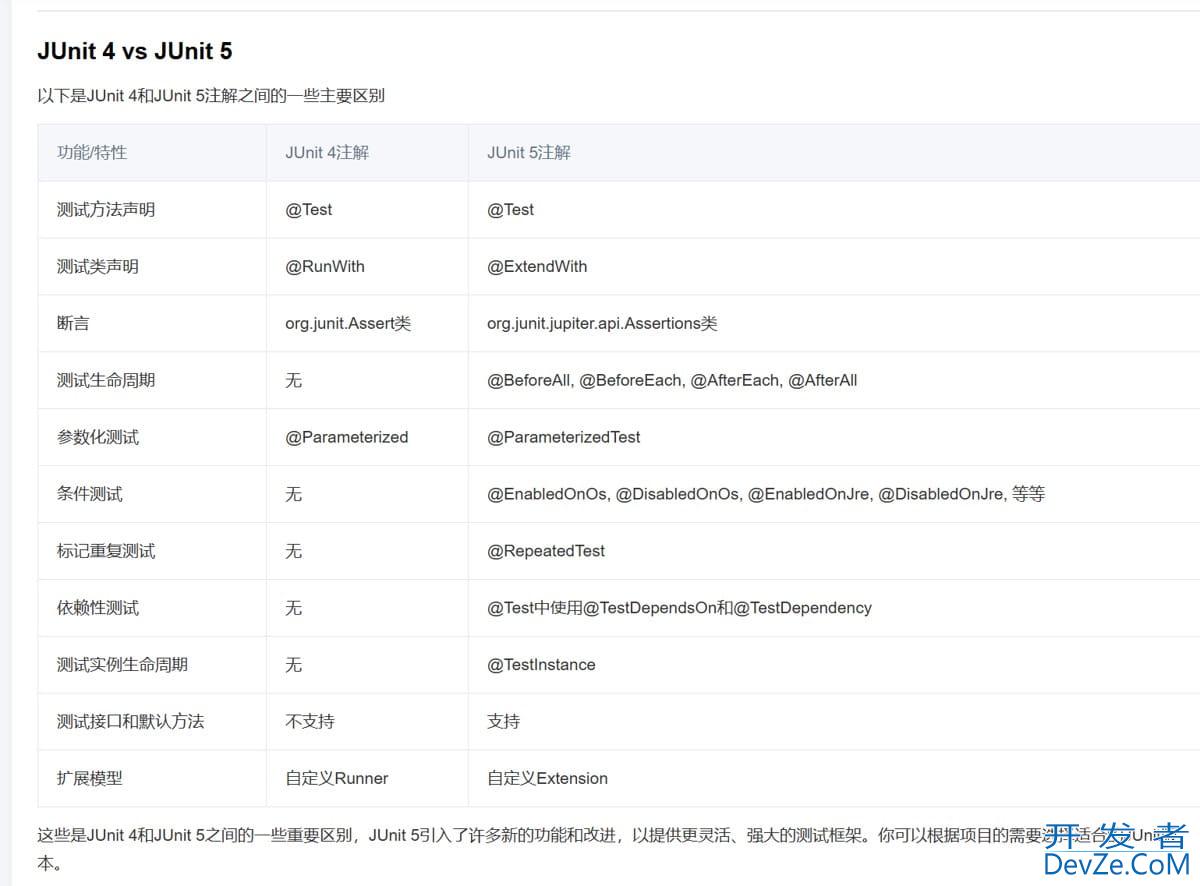
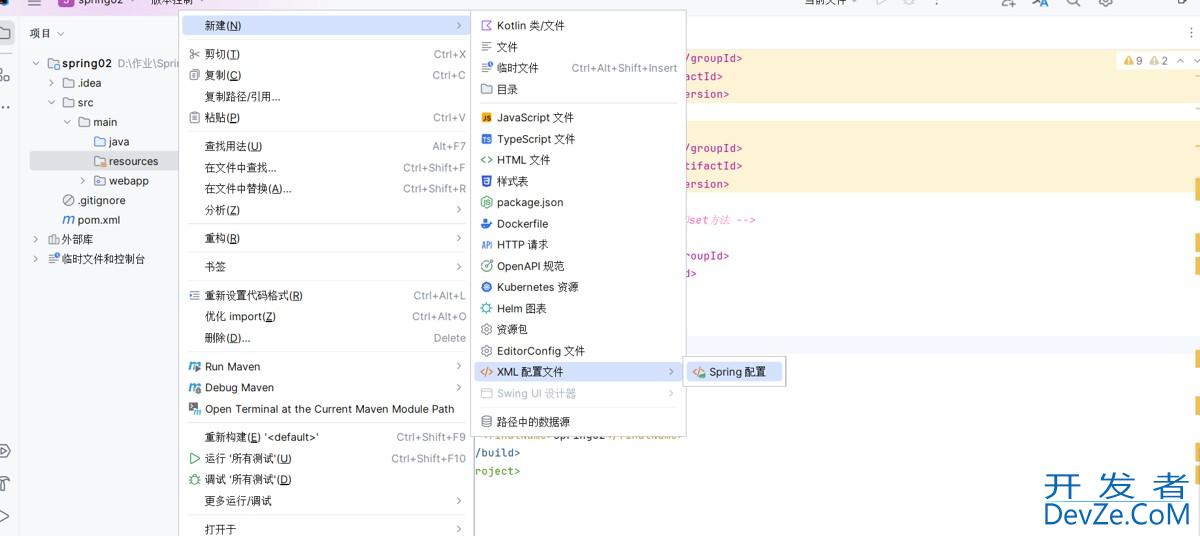
SpringBoot 整合MyBatis、Junit5的实践过程
Java调用Vue前端页面生成PDF文件的完整代码
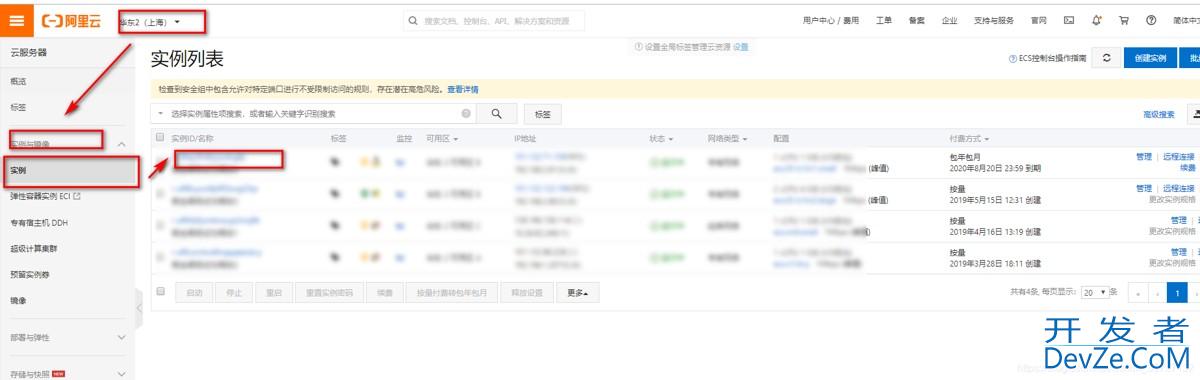
IDEA实现一键部署项目到服务器过程
Spring控制反转和依赖注入超详细讲解



 加载中,请稍侯......
加载中,请稍侯......