python+selenium编写实现爬虫过程: 1.爬虫循环处理table表,2.table表分页处理,3.网页table所有内容循环处理4.获取隐藏的href超链接内容,5.所有数据本地csv保存,[详细]
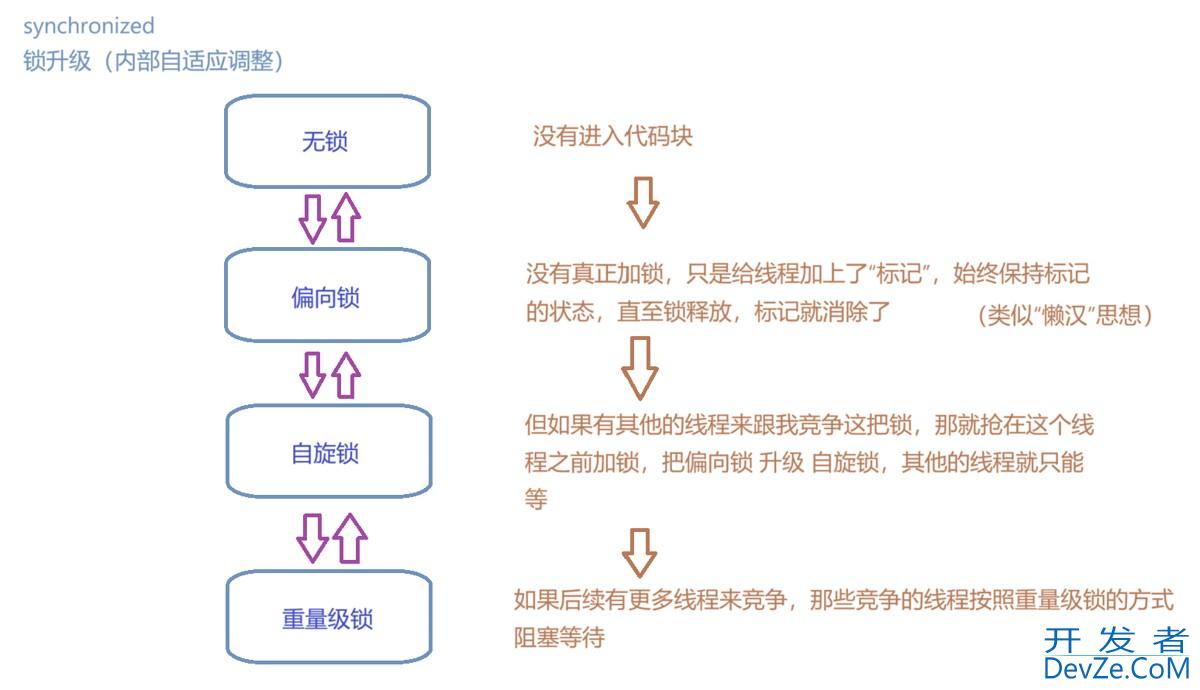
Java常见的锁策略图文详解(附实例代码)
Java对接钉钉考勤记录的完整步骤
java异步导出的实现过程
Java通过文件路径分隔符分割文件路径方式详解
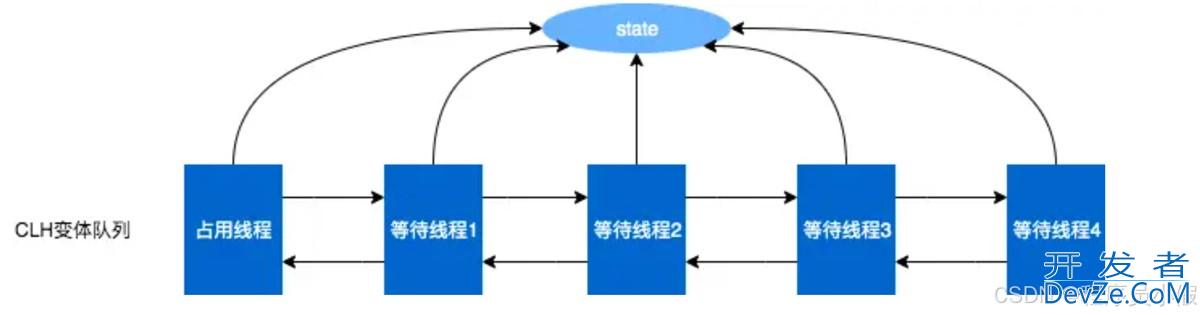
Java中的AQS入门攻略
鸿蒙打通苹果生态! 华为鸿蒙HarmonyOS 6开启与iOS/iPadOS/macOS互传体验
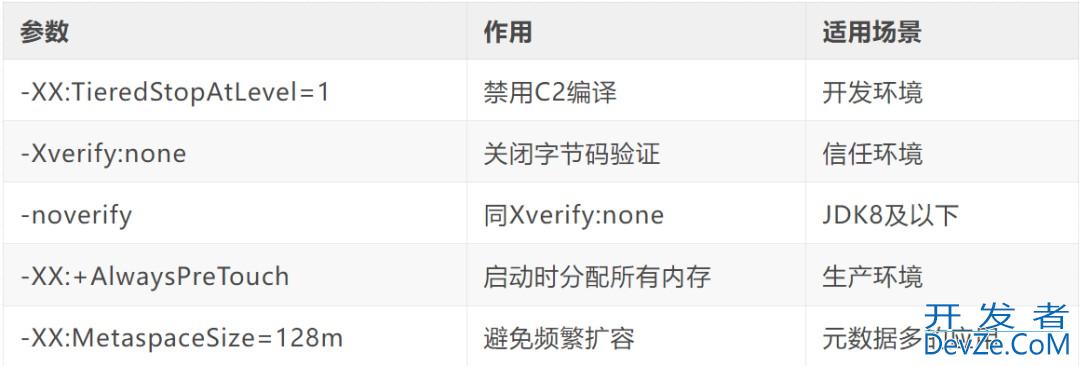
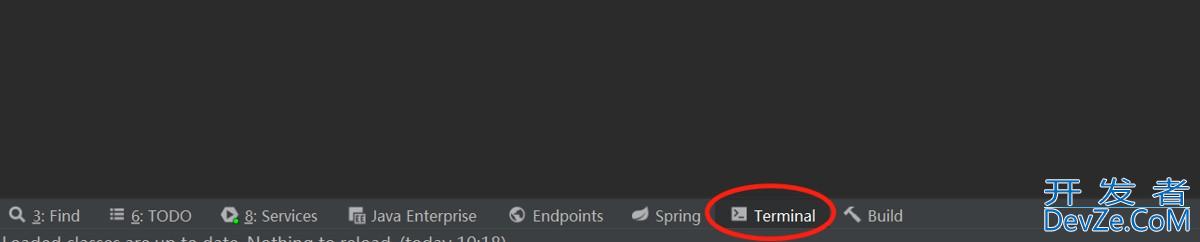
springboot项目启动优化的超强方法详解
解决IDEA下载依赖包源码报错Sources not found for:org.springframework.cloud:XXX问题



 加载中,请稍侯......
加载中,请稍侯......