9行Python3代码实现批量提取PDF文件的指定内容
目录1、引言2、代码实战2.1 介绍2.2 安装2.3 实例3、总结1、引言
小丝:鱼哥, 你有没有什么办法,提取PDF文档的内容。
0
0
0
上一篇:python实现简易计算器功能
Python中层次聚类的详细讲解:下一篇



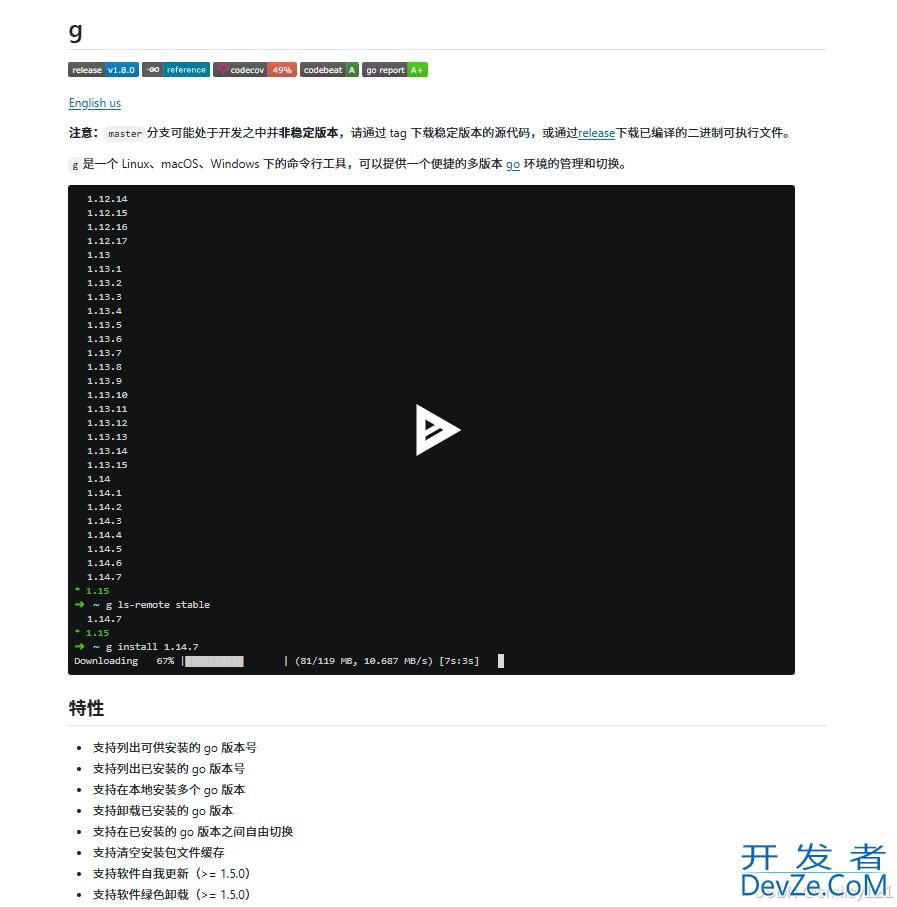
 加载中,请稍侯......
加载中,请稍侯......
精彩评论