上一篇:9行Python3代码实现批量提取PDF文件的指定内容
Python跨文件调用函数以及在一个文件中执行另一个文件:下一篇
SpringBoot Maven的操作与配置图文教程
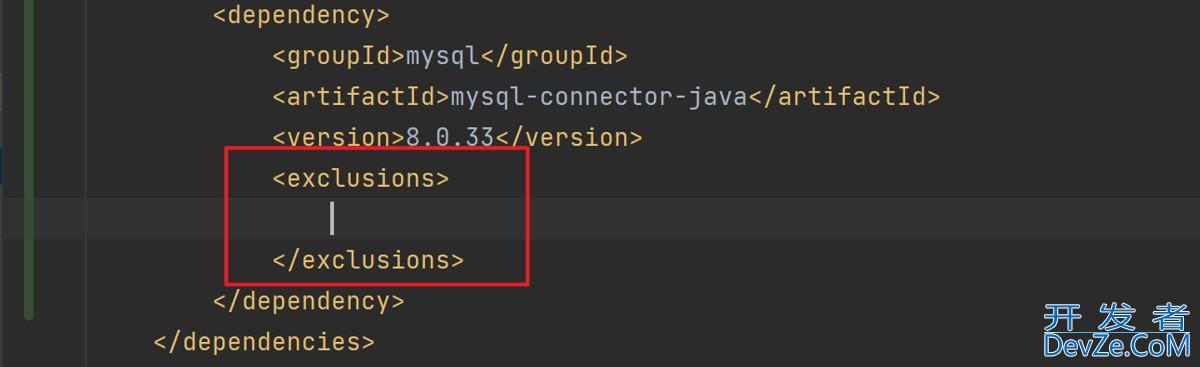
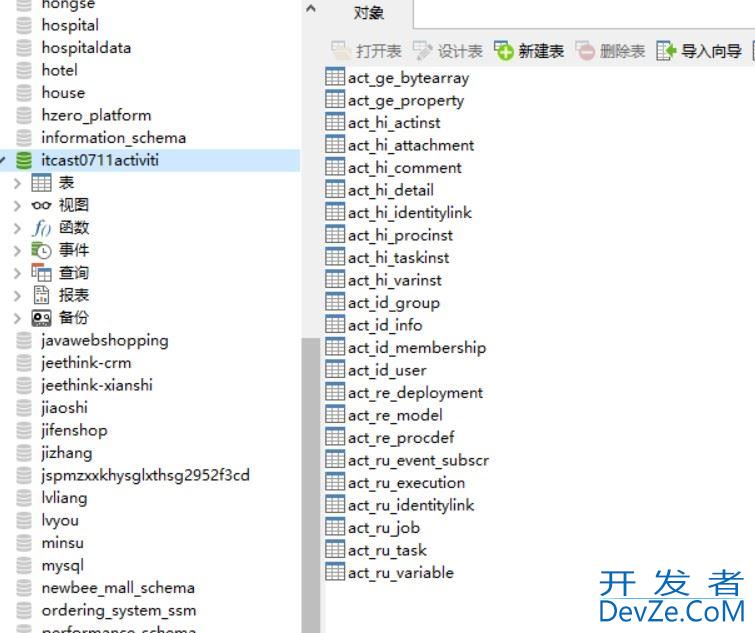
springboot集成activiti全过程
HttpServletRequest参数丢失问题及解决
Java21之字符串模板的使用小结
Golang中Context.WithCancel 的实战指南
Golang单元测试、go协程和管道示例详解
Golang中web参数校验的实现
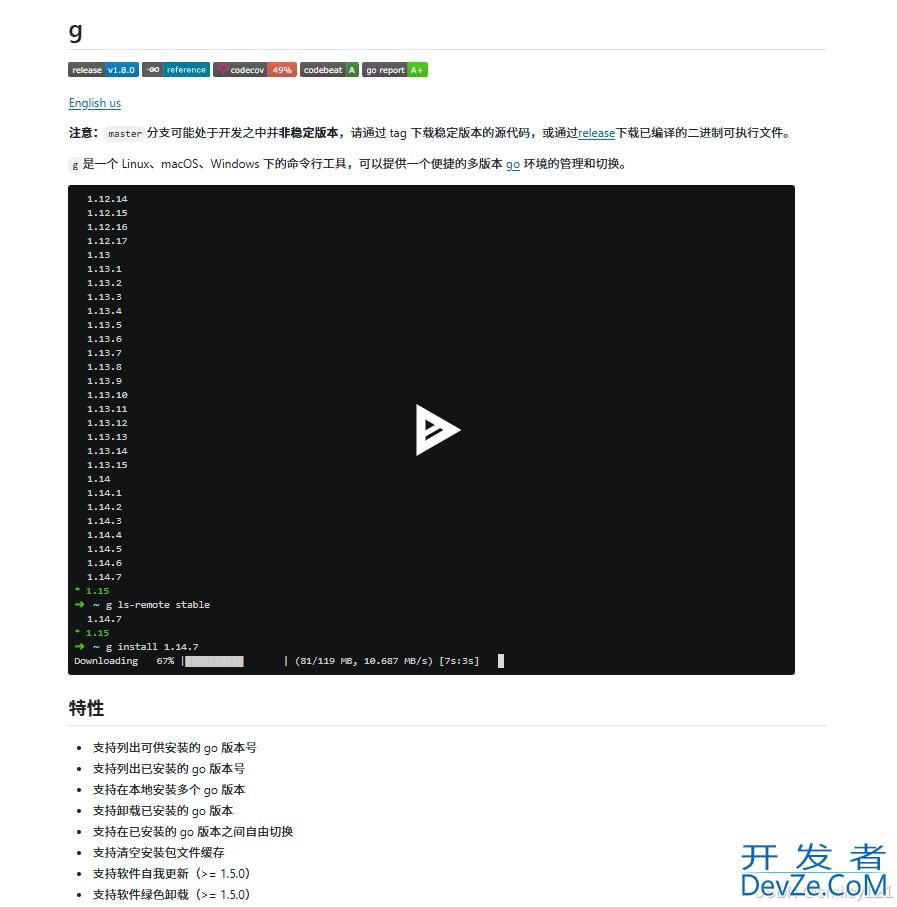
轻松管理多个Go版本之g工具安装与使用方法



 加载中,请稍侯......
加载中,请稍侯......
精彩评论