目录
- 不管怎么说,先睹为快
- 工具效果图:
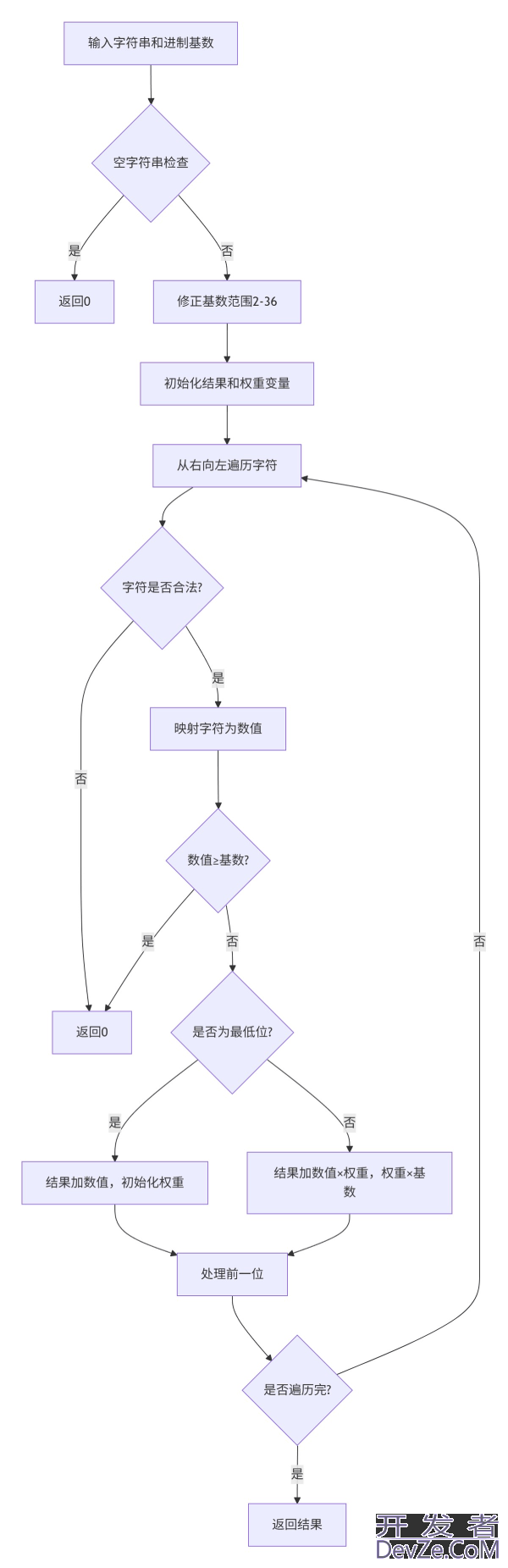
- 工具简单流程图
- 为什么需要专门的html解析库?只用正则表达式不够吗?
- BeautifulSoup:上手简单的HTML解析
- 1. 安装和准备
- 2. 按标签名访问
- 3. 用 find() 和 find_all() 精确查找 (常用方法)
- 4. 用 css 选择器 select() (简洁又强大)
- 5. 提取文本和属性
- 6. 在节点间导航 (遍历DOM树)
- lXML:追求速度和 XPath 的选择
- 1. 安装和基本使用
- 2. XPath:一种强大的节点选择语言
- 组合与比较:BeautifulSoup + lxml 是个好搭档吗?
- 动手试试:一个简单的【网页提取小工具】
- 总结:HTML解析是处理网页数据的基础
想要精找到数据却不知从何下手?这篇文章将带你了解 python 中进行 HTML 解析的常用工具,还会通过一个【网页提取小工具】的例子,看看如何将这些技术应用起来,并简单探讨一下结合智能技术自动提取正文、生成摘要和关键词的可能性。
告别手动复制粘贴:用CSS选择器与XPath高效提取网页数据
不管怎么说,先睹为快
工具效果图:

工具简单流程图

为什么需要专门的HTML解析库?只用正则表达式不够吗?
想象一下,你需要从好几个竞争对手的网站上快速抓取产品介绍,或者想从新闻网站提取最新的科技动态标题和链接。
我们拿到的网页源码,通常是类似下面这样的 HTML 结构:
<html>
<head><title>最新新闻</title></head>
<body>
<div class="news-list">
<article><h2><a href="/news/1" rel="external nofollow" >标题一</a></h2><p>摘要...</p></article>
<article><h2><a href="/news/2" rel="external nofollow" >标题二</a></h2><p>摘要...</p></article>
</div>
</body>
</html>
如果直接用正则表达式来提取这些信息,你可能会发现一些麻烦:
- 容易失效:网站稍微调整一下页面结构,写好的正则表达式可能就用不了了,维护起来比较头疼。
- 写起来复杂:对于层层嵌套或者结构比较乱的 HTML,编写和调试正则表达式本身就挺花时间的。
- 功能有限:正则表达式不太擅长处理标签之间的层级关系,比如找到某个元素的父元素或兄弟元素。
小结: 网页越来越复杂,只靠正则表达式来提取数据,往往效率不高,而且不够稳定。这时候,我们就需要更专业的工具了。
HTML解析库就是为此而生的。它们能理解 HTML 的文档结构(也就是 DOM,文档对象模型),把源码解析成一个树状的对象。这样,我们就能用更可靠、更方便的方式来找到并拿出我们想要的东西。

在 Python 里,比较常用的 HTML 解析库有这么几个:
BeautifulSoup(BS4):它的接口设计得比较友好,学起来相对容易,适合新手入门和快速做一些小工具。lxml:它是基于 C 语言库构建的,解析速度通常更快,处理不规范 HTML 的能力也比较强(容错性好),还支持 XPath 这种强大的查询语言。适合处理大型或者结构复杂的文档,或者对性能要求比较高的场景。
其他选择:
html.parser: Python 自带的,不用额外安装,但速度和容错性一般。html5lib: 据说最接近浏览器的解析方式,容错性最好,但相应地,速度会慢一些。
怎么选呢?
- 入门或者大部分情况:推荐试试
BeautifulSoup结合lxml解析器。这样既能利用BeautifulSoup的易用性,也能获得不错的性能。 - 追求更好的性能或需要处理复杂查询:可以直接上手
lxml。
接下来,咱们先从 BeautifulSoup 开始,看看怎么用它来解析 HTML。
BeautifulSoup:上手简单的HTML解析
BeautifulSoup (我们常叫它 BS4) 的设计初衷就是让 HTML 解析这事儿变得简单明了。
1. 安装和准备
# 安装 BS4 和推荐搭配使用的 lxml 解析器 pip install beautifulsoup4 lxml
在 Python 代码里这么用:
from bs4 import BeautifulSoup import requests # 用于获取网页内容 # 示例 HTML (实际通常来自 requests 获取的 response.text) html_doc = """ <html><head><title>一个简单的例子</title></head> <body> <p class="title">加粗标题</p> <p class="story">这是一个段落... <a href="http://example.com/link1" rel="external nofollow" class="sister" id="link1">链接1</a>, <a href="http://example.com/link2" rel="external nofollow" class="sister" id="link2">链接2</a> and <a href="http://example.com/link3" rel="external nofollow" class="sister" id="link3">链接3</a>; 开始了新的故事.</p> <p class="data">...</p> </body></html> """ # 初始化 BeautifulSoup 对象,告诉它我们想用 'lxml' 这个解析器 soup = BeautifulSoup(html_doc, 'lxml')
2. 按标签名访问
如果 HTML 结构比较简单,可以直接用点 (.) 加上标签名来访问第一个匹配到的标签:
print(soup.title) # 输出: <title>一个简单的例子</title> print(soup.title.name) # 输出: 'title' (标签名) print(soup.title.string) # 输出: '一个简单的例子' (标签内文本) print(soup.p) # 输出: <p class="title">加粗标题</p> (找到的第一个 p 标签)
3. 用 find() 和 find_all() 精确查找 (常用方法)
这是最常用的查找方式了,可以根据标签名、CSS 类名、ID、甚至其他属性来找。
find('tag', class_='css_class', id='id_val', attrs={'attr': 'value'}): 查找第一个符合条件的标签,找到就返回那个标签对象,找不到就返回None。find_all(...): 查找所有符合条件的标签,返回一个列表(这个列表可能是空的)。还可以用limit=N来限制最多找多少个。
举个例子: 假设我们要提取所有 CSS 类是 product-title 的 h2 标签里的文字。
# 查找所有 class='product-title' 的 h2 标签
product_titles = soup.find_all('h2', class_='product-title')
# 遍历结果列表
for title in product_titles:
# 使用 .get_text(strip=True) 获取纯文本,更稳妥
print(title.get_text(strip=True))
注意一个小细节:class vs class_
class 在 Python 里是个关键字(用来定义类),所以在 find 或 find_all 里按 CSS 类名查找时,参数名叫 class_ (后面多了个下划线)。当然,你也可以用 attrs 字典来指定:soup.find_all('a', attrs={'class': 'sister'})。
4. 用 CSS 选择器 select() (简洁又强大)
如果你熟悉 CSS,那 select() 方法会让你感觉很亲切。它的语法和 CSS 选择器几乎一样。
- 标签名:
select('p') - 类名:
select('.product-title') - ID:
select('#main-content') - 子元素:
select('div.article > h2')(找div下直接的h2子元素) - 后代元素:
select('div#news-list article')(找div下所有层级的article元素) - 属性:
select('a[target="_blank"]')(找target属性是_blank的a标签)
举个例子: 提取新闻列表(假设是 div.news-list)里所有文章标题(在 h2 里的链接 a)。
# 使用 CSS 选择器定位
news_links = soup.select('div.news-list h2 a')
for link in news_links:
# link.string 获取文本, link['href'] 获取 href 属性
print(f"标题: {link.string.strip()}, 链接: {link['href']}")

5. 提取文本和属性
找到目标标签后,我们通常关心的是里面的文字内容,或者是它的某个属性值(比如链接的 href)。
获取文本:
.string: 这个属性比较"挑剔",只有当标签里没有其他嵌套标签,纯粹是文本时才好用,否则可能返回None。.get_text(): (推荐使用) 这个方法能获取标签内所有的文本内容,包括所有子标签里的。strip=True: 参数设为True可以去掉文本开头和结尾的空白字符(像空格、换行符)。separator='sep': 如果标签内有多段文本(比如被<br>分隔),可以用这个参数指定一个分隔符把它们连接起来。
获取属性:
tag['attr_name']: 像访问字典一样用方括号加属性名。但如果这个属性不存在,代码会报错。tag.get('attr_name'): (推荐使用) 这个方法更安全,如果属性不存在,它会返回None,而不是报错。
举个例子: 获取页面上所有链接的文字和 URL。
all_links = soup.find_all('a')
for link in all_links:
link_text = link.get_text(strip=True)
link_url = link.get('href') # 用 get() 好处是,万一这个 a 标签没有 href 属性也不会出错
if link_url: # 最好判断一下确实拿到了 URL 再打印
print(f"链接文字: {link_text}, URL: {link_url}")
6. 在节点间导航 (遍历DOM树)
有时候,我们找到了一个节点,还需要找它的父节点、子节点或者旁边的兄弟节点。
.contents/.children: 获取直接子节点的列表 / 迭代器。.descendants: 获取所有后代节点(包括文字节点)的迭代器。.parent/.parents: 获取直接父节点 / 所有祖先节点的迭代器。.next_sibling/.previous_sibling: 获取下一个/上一个兄弟节点。注意,这可能拿到的是两个标签之间的空白文本节点,不一定是标签。.next_siblings/.previous_siblings: 获取后面/前面所有兄弟节点的迭代器。.find_next_sibling(s)()/.find_previous_sibling(s)(): (比较实用) 这组方法可以查找符合条件的下一个/上一个标签兄弟,能帮你跳过那些文本节点。
举个例子: 找到标题标签后,想找它后面紧跟着的价格标签(假设是个 span)。
# 假设 title_tag 是已找到的标题标签
# 查找其后第一个 class='price' 的 span 兄弟标签
price_tag = title_tag.find_next_sibling('span', class_='price')
if price_tag:
print(f"价格是: {price_tag.get_text(strip=True)}")
一个参数 recursive=False:
find_all() 等查找方法时,可以加上 recursive=False 这个参数。它的意思是只查找当前标签的直接子节点,不再往更深层级的后代节点里查找。
lxml:追求速度和 XPath 的选择
lxml 这个库以速度快和解析能力强而出名,特别适合处理那些很大或者结构很复杂的 HTML/XM编程客栈L 文档。
1. 安装和基本使用
pip install lxml
from lxml import etree
# 直接解析 HTML 字符串,lxml 会尝试修复不规范的 HTML
tree = etree.HTML(html_doc) # html_doc 是之前的示例
# 也可以从文件或网络响应解析
# tree = etree.HTML(response.text)
# parser = etree.HTMLParser(encoding='utf-8') # 指定编码
# tree = etree.parse('your_page.html', parser)
2. XPath:一种强大的节点选择语言
XPath 提供了一套灵活的语法规则,让你可以在文档树里精确地定位到想要的节点。
常用的语法规则:
/: 从根节点开始选。//: 从文档中任意位置开始查找(这个最常用)。 比如//div就是找所有的 div 元素。.: 代表当前节点。..: 代表父节点。tag_name: 选择指定标签名的节点。 比如a就是找所有 a 标签。@attr_name: 选择属性。 比如//@href就是找所有 href 属性。*: 通配符,匹配任何元素节点。[@attr='value']: 根据属性值精确匹配。 比如//a[@id='link1']就是找 id 等于 ‘link1’ 的 a 标签。[contains(@attr, 'substr')]: 检查属性值是否包含某个子字符串。 比如//div[contains(@class, 'article')]找 class 包含 ‘article’ 的 div。[starts-with(@attr, 'prefix')]: 检查属性值是否以某个前缀开头。[N]: 选择第 N 个匹配的元素(注意:XPath 的索引是从 1 开始算的,不是 0!)。 比如//ul/li[1]找 ul 下的第一个 li。text(): 获取节点的文本内容。 比如//p/text()获取 p 标签直接包含的文本。|: 表示"或"逻辑,可以合并多个路径的结果。 比如//h2/text() | //h3/text()同时获取 h2 和 h3 的文本。

用 XPath 试试(还是用前面的 html_doc):
# 获取 class='story' 的 p 下面第一个 a 标签的文本
first_link_text = tree.xpath('//p[@class="story"]/a[1]/text()') # a[1] 指的是第一个 a 标签
print(first_link_text[0])
XPath 的一些优点:
- 轴(Axis)选择: 能支持更复杂的节点关系定位,比如找前面的兄弟节点、祖先节点等等,比 CSS 选择器更灵活。
- 内置函数: 提供了一些有用的函数,像
count()计数,sum()求和,contains()判断包含,normalize-space()清理空白字符等。
3. lxml 其实也支持 CSS 选择器
lxml 借助一个叫 cssselect 的库,也提供了对 CSS 选择js器的支持。你需要先安装它:pip install cssselect。
# 使用 .cssselect() 方法
link1_css_lxml = tree.cssselect('a#link1')
print(link1_css_lxml[0].text) # Element 对象有 .text 属性
story_links_css_lxml = tree.cssselect('p.story a.sister')
print(f"CSS 选择器找到 {len(story_links_css_lxml)} 个 sister 链接")
XPath 和 CSS 选择器怎么选?
- 学习难度: 一般认为 CSS 选择器更容易上手。
- 功能: XPath 功能更强大,特别是在处理复杂的路径、条件判断或者需要利用轴选择的时候。
- 性能 (在 lxml 内部): 两者性能通常差不多,有时候 XPath 甚至可能更快一点。
建议: 先掌握好 CSS 选择器,它能搞定大部分场景。如果遇到 CSS 选择器处理起来很麻烦或者实现不了的需求,再考虑用 XPath。
组合与比较:BeautifulSoup + lxml 是个好搭档吗?
把 BeautifulSoup 相对友好的接口和 lxml 的高速解析能力结合起来,确实是个常见的做法,能在开发效率和运行速度之间取得不错的平衡。
# 指定 lxml 作为 BS4 的解析器 soup = BeautifulSoup(html_doc, 'lxml') # 然后就可以照常使用 soup.find, soup.select 这些 BS4 的方法了
性能特点大概是这样:

- 速度: 通常情况下,直接用
lxml最快 >BS4+lxml组合 >BS4+html.parser(Python自带)。处理大文件时,lxml的速度优势会更明显。 - 内存:
lxml通常也更节省内存。 - 易用性:
BeautifulSoup的 API 设计更符合 Python 的习惯,学起来感觉更顺手一些。 - 容错性:
lxml和html5lib在处理不太规范的 HTML 代码时,表现比较好,不容易出错。
怎么选比较合适?
- 写一些日常脚本、教学演示、或者快速搭个原型: 用
BeautifulSoup+lxml这个组合挺好,开发体验不错,性能也足够用了。 - 开发大规模爬虫、或者对性能要求比较高的应用: 可以优先考虑直接使用
lxml。 - 需要处理非常不规范、甚至可以说是"脏"的 HTML: 可以试试
BeautifulSoup+html5lib这个组合,它的容错性最好。
动手试试:一个简单的【网页提取小工具】
现在,咱们把前面学到的东西用起来,做一个简单的【网页提取小工具】。
这个小工具有啥用?
- 学习研究: 比如快速扒某个网页的主要文字内容,或者看看文献摘要。
- 信息收集: 从一些报告、资讯网站抓取文本,做初步的摘要和关键词提取。
- 内容辅助: 找资料时,快速获取网页主体内容,帮助提炼重点。
核心功能(可以考虑后续扩展):
- 输入一个网址(URL),尝试提取出页面的主要文本内容。
- 生成一个简单的摘要(比如就提取前几句话)。
- 提取一些关键词(比如基于词频统计)。
- (扩展思路:可以对接外部的智能处理服务,做得更智能)
技术选型: Python + Flask (做个简单的网页界面) + requests (获取网页) + BeautifulSoup/lxml (解析HTML) + (可选的智能接口)
界面大概长这样:
一个简单的页面,有个输入框让你填网址,一个提交按钮,下面显示提取结果(比如原文预览、摘要、关键词)。
核心代码逻辑 (用 Flask + BeautifulSoup 举例,并标注了可扩展的地方):
# --- codes/web_content_extractor/app.py ---
# (代码和之前版本差不多,这里重点看逻辑和注释)
# ... Flask 初始化和模板渲染设置 ...
# ... 可以先定义简单的摘要和关键词提取函数 (simple_summarizer, simple_keyword_extractor) ...
@app.route('/', methods=['GET', 'POST'])
def index():
result = None
error = None
if request.method == 'POST':
url = request.form.get('url')
if url:
# 模拟浏览器发请求,加个 User-Agent 通常是个好习惯
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
try:
response = requests.get(url, headers=headers, timeout=10) # 设置超时防止卡死
response.raise_for_status() # 如果请求失败 (例如 404, 500),这里会抛出异常
# 尝试让 requests 自动检测编码,或者根据情况手动指定 response.encoding = 'utf-8'
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, 'lxml') # 用 lxml 解析器
# --- 提取主要内容的逻辑 ---
# 这部分是难点,没有完美通用的方法,通常需要尝试多种策略
main_content_html = None
# 策略1: 尝试查找常见的表示主要内容的标签或类名
# (这些选择器是经验性的,可能需要根据目标网站调整)
content_selectors = ['article', 'main', '.content', '#main', '.post-body', '.entry-content', '.article-content']
for selector in content_selectors:
javascript content_element = soup.select_one(selector) # select_one 找到第一个匹配的
if content_element:
# 简单判断下内容长度,避免选中一个空标签或无关的小区域
if len(content_element.get_text(strip=True)) > 100: # 阈值可以调整
main_content_html = content_element
print(f"策略1命中: {selector}")
break
# 策略2: 如果策略1没找到,尝试清理掉干扰元素(导航、页脚、广告等),然后用 body
if not main_content_html:
print("尝试策略2: 清理通用模块...")
# 创建一个副本进行清理操作,以免影响原始 soup 对象
soup_for_cleaning = BeautifulSoup(str(soup), 'lxml')
# 要移除的元素选择器列表 (根据常见情况列出,可能需要补充)
elements_to_remove = ['script', 'style', 'header', 'footer', 'nav', '.sidebar', '.ads', '.comment', '#comments', '.related-posts']
for selector in elements_to_remove:
try:
for tag in soup_for_cleaning.select(selector):
tag.decompose() # decompose() 会将标签及其内容从树中移除
except Exception as e:
# select 找不到元素不会报错,但其他操作可能出错
print(f"清理 {selector} 时可能出错: {e}") # 记录下日志或打印出来
# 清理后,假设 body 里剩下的主要是正文
if soup_for_cleaning.body:
main_content_html = soup_for_cleaning.body
else:
# 如果连 body 都没有,那就没办法了
main_content_html = soup_for_cleaning # 退而求其次
# 从选中的 HTML 块中提取纯文本
main_text = "未能有效提取内容。"
if main_content_html:
# get_text 获取所有文本,用换行符分隔,并去除首尾空白
raw_text = main_content_html.get_text(separator='\n', strip=True)
# 清理多余的空行
main_text = re.sub(r'\n\s*\n+', '\n', raw_text)
# --- 扩展点:对接外部智能处理服务 ---
# 如果有条件,可以在这里把提取到的 main_text 发送给外部 API
# 比如:
# summary = call_external_summary_api(main_text)
# keywords = call_external_keyword_api(main_text)
# 目前,我们先用之前定义的简单版本
summary = simple_summarizer(main_text) # 假设有这个函数
keywords = simple_keyword_extractor(main_text) # 假设有这个函数
result = {
'url': url,
# 只显示部分内容作为预览,避免页面过长
'content': main_text[:1000] + "... (预览)" if len(main_text) > 1000 else main_text,
'summary': summary,
'keywords': keywords
}
except requests.exceptions.Timeout:
error = "请求超时,目标网站可能响应慢或无法访问。"
except requests.exceptions.RequestException as e:
error = f"请求网页时出错: {e}"
except Exception as e:
error = f"处理过程中发生错误: {type(e).__name__} - {e}"
# 最好在后台记录详细错误日志
app.logger.error(f"处理 URL {url} 出错: {e}", exc_info=True)
else:
error = "请输入一个网址。"
# 把结果传给 HTML 模板去显示
return render_template('index.html', result=result, error=error)
# ... Flask 应用的启动代码 ...
(其他相关文件如 index.html, requirements.txt, README.md 的内容也需要相应调整,这里重点展示了 app.py 的核心逻辑和思考过程)
探索更智能的处理:从提取到理解
上面这个代码只是搭了个基础架子,更有意思的地方在于,它可以作为一个起点,去对接各种文本处理的 API 服务:
- 更好的摘要: 不再是简单取前几句,而是调用专门的摘要服务,传入
main_text和要求(比如"请将这段文字总结为150字左右的核心观点")。 - 更准的关键词: 同样,调用关键词提取服务,让它从
main_text中找出最相关的几个词。 - 还能做什么:
- 情感判断:分析提取出来的评论是好评还是差评。
- 内容分类:www.devze.com自动判断文章属于哪个领域(科技、体育、娱乐等)。
- 内容改写/生成:基于提取的内容,进行二次创作。
- 信息问答:针对提取出来的长篇内容,回答用户提出的相关问题。
安全提醒:API 密钥要放好
如果你调用的服务需要 API Key(访问凭证),千万别直接写在代码里。推荐用 .env 文件来管理:
- 安装
python-dotenv库:pip install python-dotenv - 在项目根目录下创建一个名为
.env的文件,里面写YOUR_API_KEY='你的密钥' - 在 Python 代码里加载:
import os from dotenv import load_dotenv load_dotenv() # 加载 .env 文件中的环境变量 api_key = os.getenv('YOUR_API_KEY') # 从环境变量读取 # 然后用 api_key 去调用服务- 记得把
.env文件添加到.gitignore里,避免上传到代码仓库。
运行和测试:
按照 README.md 文件里的说明(如果还没有,需要创建一个),在你的电脑上把这个小工具跑起来(通常是运行 python app.py),然后在浏览器里打开 http://127.0.0.1:5000 (或者 Flask 启动时提示的地址),输入一些不同的网页链接试试看效果。
注意: 这个工具仅用于学习,请勿用于非法用途。
本次代码未传仓库,想要学习,请评论区交流
总结:HTML解析是处理网页数据的基础
通过这篇文章,我们一起了解了 Python 里常用的 HTML 解析库 BeautifulSoup 和 lxml,熟悉了 CSS 选择器和 XPath 这两种定位元素的方法,还动手尝试做了一个简单的【网页提取小工具】,并探讨了结合外部智能服务提升功能的可能性。
接下来可以学点啥?
- 处理动态加载的网页: 很多网页内容是用 JavaScript 渲染出来的,只用
requests拿不到。可以了解下 Selenium、Playwright 这些可以模拟浏览器行为的工具。 - 更高级的选择器技巧: 深入学习 XPath 的轴(axis)、函数,以及 CSS 的一些高级用法。
- 爬虫框架: 如果需要做更复杂的爬虫项目,可以了解下 Scrapy 这样的专业框架。
- 反爬虫和应对:js 网站会有各种反爬措施,需要学习如何伪装 User-Agent、使用代理 IP、处理 Cookie、识别验证码等。
- 异步爬虫: 为了提高爬取效率,可以研究下用
asyncio配合aiohttp来实现异步并发请求。
n 里常用的 HTML 解析库 BeautifulSoup 和 lxml,熟悉了 CSS 选择器和 XPath 这两种定位元素的方法,还动手尝试做了一个简单的【网页提取小工具】,并探讨了结合外部智能服务提升功能的可能性。
接下来可以学点啥?
- 处理动态加载的网页: 很多网页内容是用 javascript 渲染出来的,只用
requests拿不到。可以了解下 Selenium、Playwright 这些可以模拟浏览器行为的工具。 - 更高级的选择器技巧: 深入学习 XPath 的轴(axis)、函数,以及 CSS 的一些高级用法。
- 爬虫框架: 如果需要做更复杂的爬虫项目,可以了解下 Scrapy 这样的专业框架。
- 反爬虫和应对: 网站会有各种反爬措施,需要学习如何伪装 User-Agent、使用代理 IP、处理 Cookie、识别验证码等。
- 异步爬虫: 为了提高爬取效率,可以研究下用
asyncio配合aiohttp来实现异步并发请求。
到此这篇关于Python HTML解析:BeautifulSoup,Lxml,XPath使用教程的文章就介绍到这了,更多相关Python HTML解析:BeautifulSoup,Lxml,XPath内容请搜索编程客栈(www.devze.com)以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程客栈(www.devze.com)!

 加载中,请稍侯......
加载中,请稍侯......
精彩评论